Some Background on GPUs
This section gives a very light overview of what GPUs are and some relevant information on how they are organised for developers.
What are GPUs?
You have probably heard of a type of computer chip called a central processing unit (CPU). GPUs are a different type of computer chip. The major difference between CPUs and GPUs is how each chip is organised. Whereas CPUs tend to have a small number of threads, GPUs can have orders of magnitudes more. On GPUs, you can write code that parallelises across thousands of threads, something that would be impossible on CPUs without great effort and expense.
How are GPUs organised?
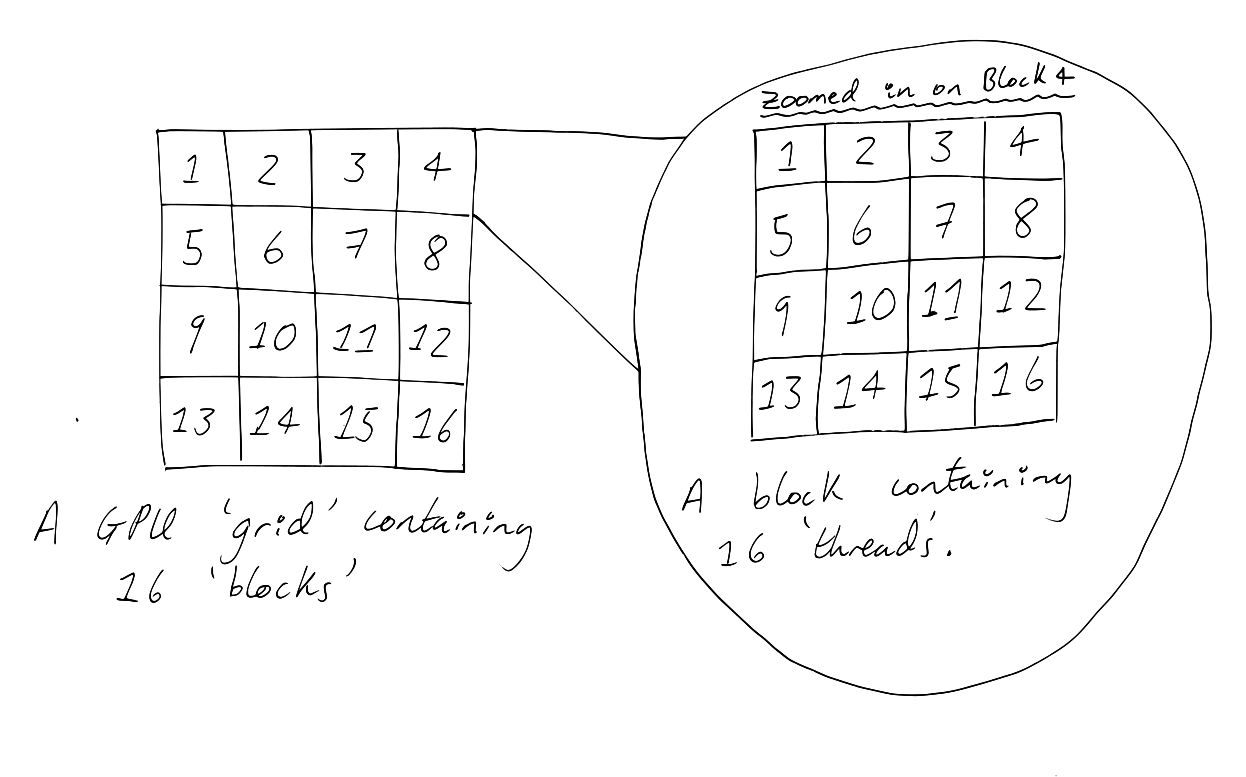
Each GPU contains a 'grid' of 'blocks'. Each block in that grid is itself composed of a matrix of 'threads'. Programs written to run on GPUs can be parallelised over blocks or threads or both. Each block has an index representing its position in the grid, and each thread has an index representing its position within its block. When we run a function in parallel on a GPU using Julia, we can specify how many blocks and threads we want it to run on. For example, the GPU in my laptop has 65535 blocks and each block contains 1024 threads. I could use the GPU in my laptop to create a grid like the one above by telling my GPU to run a function on 16 blocks and 16 threads. If I try to run my function on more threads or blocks than my GPU has, an InexactError is thrown (somewhat cryptically) and my function fails to execute.
Host and Device
Software written for GPUs rarely runs entirely on GPUs. Usually, at least a small part of GPU compatible software will run on CPUs. For example, copying data from CPUs to GPUs is a required step for most GPU software, and the copying instruction will need to execute at least partly on a CPU. Because GPU software typically executes instructions on both CPUs and GPUs, it is useful to have some terminology to describe where a particular line of code is being executed. Code that executes on CPUs is commonly described as executing 'on the host', whilst code executing on GPUs is described as executing 'on the device'. We can also use the terms 'host' and 'device' to describe where data lives in memory and operations copying data between CPUs and GPUs.
Kernel
A common way to organise code that will run on a GPU is to write a function that will execute on the GPU. This function is typically called after all the data required by the function has been copied from host (CPU) to device (GPU). Because the function is typically executed thousands of times in parallel, the function that will execute on the GPU is given the special name of 'kernel'.
CUDA
We will refer a lot to CUDA in this tutorial, so what is it? The CUDA Architecture is the architecture used by NVIDIA's General Purpose GPUs (GPGPUs). To facilitate using GPUs with this architecture for general purpose computing, NVIDIA created CUDA C, a language closely based on C. They additionally created the CUDA toolkit, which is required to compile CUDA C code. Many of the functions in CUDAnative and CUDAdrv, two of the Julia packages covered in this tutorial, are highly analogous to functions in CUDA C. These packages depend upon the CUDA toolkit or libraries from it, and rely upon the GPU they are running on having a CUDA architecture.