Shared Memory and Synchronisation
Following our example of vector addition in the previous section, you may be left wondering what the point of making a distinction between blocks and threads is. This section should make this clear.
You may recall from "Some Background on GPUs" that GPUs are composed of grids of blocks, where each block contains threads. In the drawing below, we have deployed a grid of 16 blocks each containing 16 threads (@cuda threads = 16, blocks = 16).
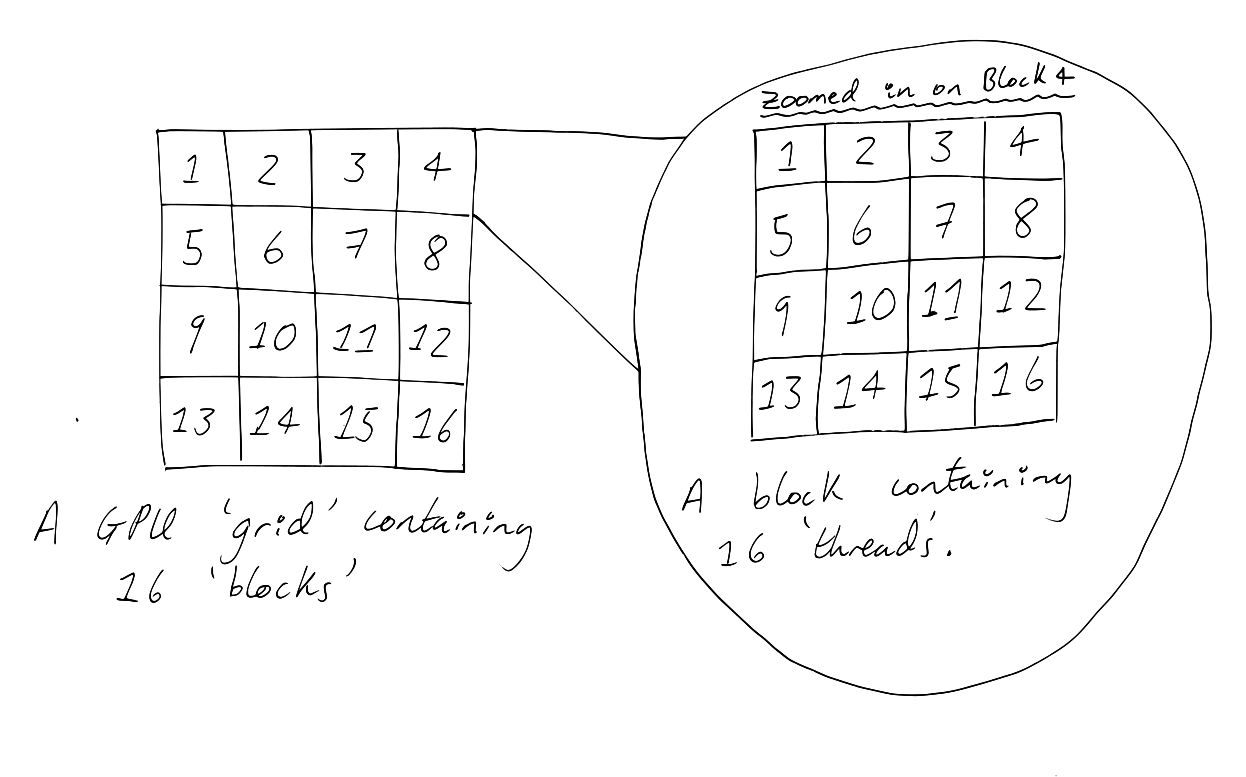
In addition to threads, each block contains shared memory. Shared memory is memory which can be read and written to by all the threads in a given block. Shared memory cannot be accessed by threads not in the specified block. This is illustrated in the diagram below.
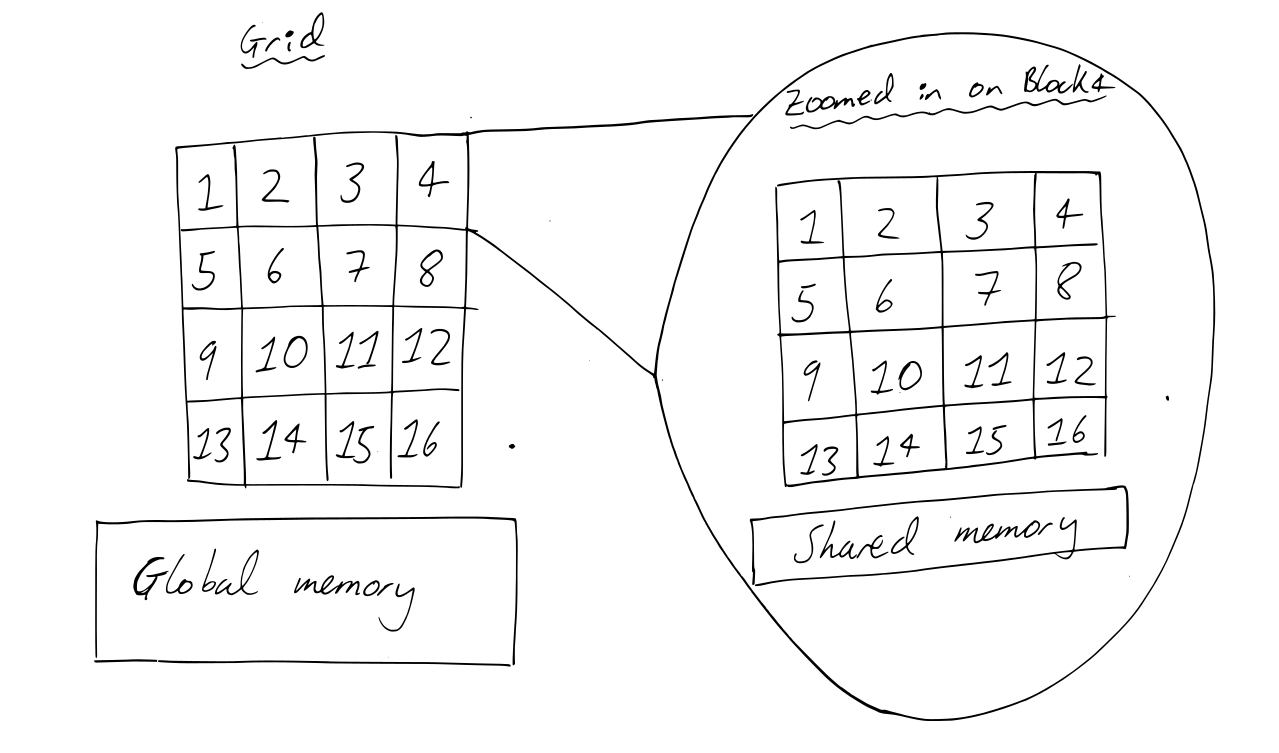
In the code we wrote for vector addition, we did not use shared memory. Instead we used global memory. Global memory can be accessed from all threads, regardless of what block they live in, but has the disadvantage of taking a lot longer to read from compared with shared memory. There are two main reasons we might use shared memory in a program:
- It can be useful to have threads which can 'communicate' with each other via shared memory.
- If we have a kernel that frequently has to read from memory, it might be quicker to have it read from shared rather than global memory (but this very much depends on your particular algorithm).
Of course, there is an obvious potential disadvantage to using shared memory. Giving multiple threads the capability to read and write from the same memory is potentially powerful. However it is also potentially dangerous. Now it is possible for threads to try to write to the same location in memory simultaneously. If we want there to be a dependency between threads, where thread A reads the results written by thread B, there is no automatic guarantee that thread A will not try to read the results before thread B has written them. We need a method to synchronise threads so this type of situation can be avoided. Fortunately, such a method exists as part of CUDAnative.
Vector Dot Product
We will use a vector dot product to explore some of the ideas introduced above. A vector dot product is when each of the elements of a vector is multiplied by the corresponding element in a second vector. Then, all of the multiplied elements are added together to give a single number as a result.
As before, we begin our script by loading the Julia packages we need to write GPU compatible code.
using CuArrays, CUDAnative, CUDAdrvNext, we need to write the kernel. It is a lot to take in, but do not worry, we will go through it step by step.
function dot(a,b,c, N, threadsPerBlock, blocksPerGrid)
# Set up shared memory cache for this current block.
cache = @cuDynamicSharedMem(Int64, threadsPerBlock)
# Initialise some variables.
tid = (threadIdx().x - 1) + (blockIdx().x - 1) * blockDim().x
totalThreads = blockDim().x * gridDim().x
cacheIndex = threadIdx().x - 1
temp = 0
# Iterate over vector to do dot product in parallel way
while tid < N
temp += a[tid + 1] * b[tid + 1]
tid += totalThreads
end
# set cache values
cache[cacheIndex + 1] = temp
# synchronise threads
sync_threads()
# In the step below, we add up all of the values stored in the cache
i::Int = blockDim().x ÷ 2
while i!=0
if cacheIndex < i
cache[cacheIndex + 1] += cache[cacheIndex + i + 1]
end
sync_threads()
i = i ÷ 2
end
# cache[1] now contains the sum of vector dot product calculations done in
# this block, so we write it to c
if cacheIndex == 0
c[blockIdx().x] = cache[1]
end
return nothing
endThis is more complicated than the vector addition kernel, so let's work through it bit by bit. First of all, it is important to keep in mind that dot() (the kernel) is intended to be called across multiple blocks AND threads. Below is the line in main() in which the kernel is called:
@cuda blocks = blocksPerGrid threads = threadsPerBlock shmem =
(threadsPerBlock * sizeof(Int64)) dot(a,b,c, N, threadsPerBlock, blocksPerGrid)Note that we specify both a number of blocks (blocksPerGrid) and a number of threads (threadsPerBlock) on which the kernel will be executed. This means dot() will be executed on threadsPerBlock number of threads in blocksPerGrid number of blocks. For example, if threadsPerBlock = 10 and blocksPerGrid = 10, we would deploy 10 blocks each containing 10 threads and execute the dot() on each of those threads, meaning dot() would be executed 100 times in parallel. We also specify a value for a flag called shmem for the first time. shmem specifies the amount of shared memory that needs to be allocated in each block for dot(), and will be discussed in more detail later in this section.
Before we start dissecting the kernel line by line, it would be useful to get a brief overview of what it is doing. On each thread executing the kernel, the kernel begins by calculating the product of a subset of the elements in a and b and storing the results in an array in shared memory. In the second part of the kernel, the values in the array are summed. However, we should not get ahead of ourselves, so we will start dissecting this function by focusing on the lines below:
function dot(a,b,c, N, threadsPerBlock, blocksPerGrid)
# Set up shared memory cache for this current block.
cache = @cuDynamicSharedMem(Int64, threadsPerBlock)Here, we are setting a variable called cache to the output of a function call to @cuDynamicSharedMem. As the comment suggests, this is required to create a cache of shared memory that can be accessed by all the threads in the current block. @cuDynamicSharedMem is a function from CUDAnative which allocates an array in dynamic shared memory on the GPU. The first argument specifies the type of elements in the array and the second argument specifies the dimensions of the array. So
cache = @cuDynamicSharedMem(Int64, threadsPerBlock)allocates an array in shared memory with the dimensions threadsPerBlock, where each element in the array is of type Int64.
So now we have an array of size threadsPerBlock in shared memory which we can fill with Int64s. Next we set the value of the thread index (tid):
# Initialise some variables.
tid = (threadIdx().x - 1) + (blockIdx().x - 1) * blockDim().xThis is the first time we have mixed up thread and block indexes in the same kernel! So what is going on?
The aim of this line of code is to generate a unique thread index for each thread. threadIdx().x gives the index for the current thread inside the current block. So threadIdx().x is not sufficient by itself because we are launching the kernel over multiple blocks. Each block has a thread with the index 1 (so threadIdx().x = 1), a second thread with the index 2 (threadIdx().x = 2) and so on, so we need a different approach to generate a unique thread index. blockDim().x gives number of threads in a block, which is the same for each block in a GPU. By multiplying the block index minus one (blockIdx().x - 1) and the number of threads in a block (blockDim().x), we obtain the total number of threads in all blocks before the one we are currently in. Then we add the thread index (threadIdx().x) in the current block to this total, thus generating a unique thread index for each thread across all blocks. This approach is illustrated below.
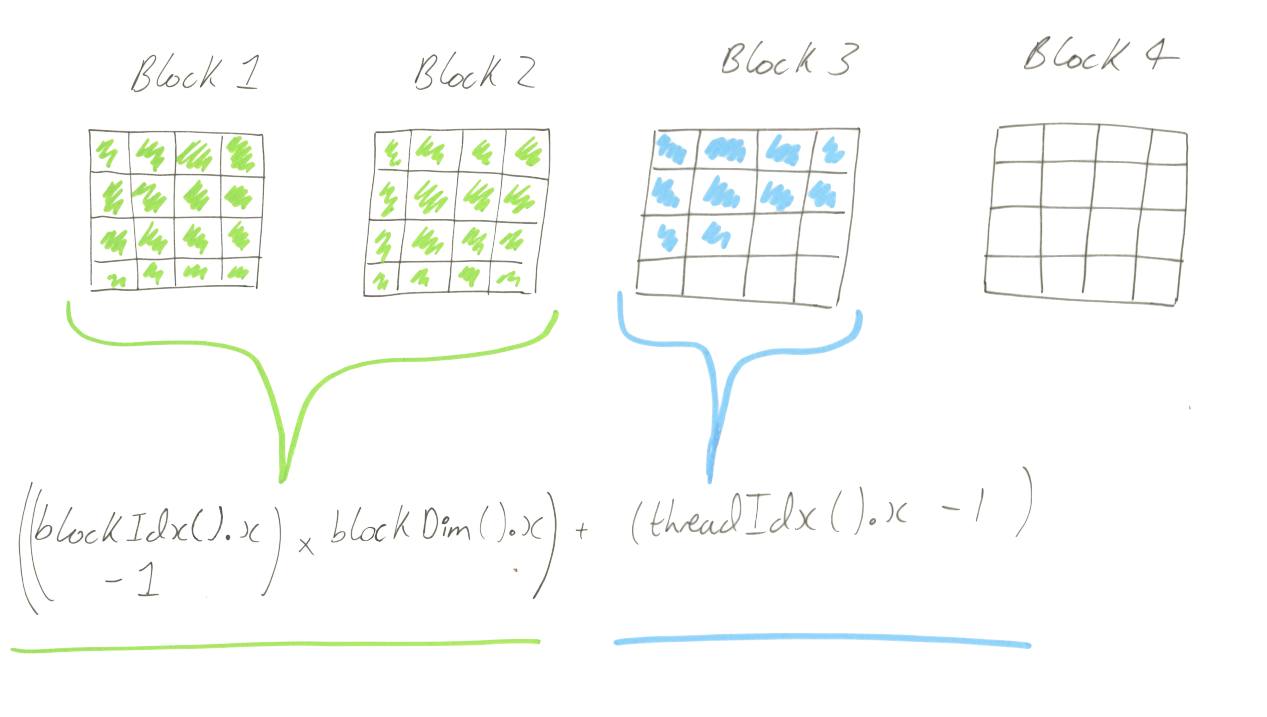
A final thing to note is that we subtract one from threadIdx().x and blockIdx().x. This is because Julia is tragically a one indexed programming language. You will notice a lot of plus and minus ones in this example, they are all there for this reason and whilst you are getting your head around the core concepts you should do your best to ignore them.
Fortunately the next three lines are conceptually a lot simpler:
cacheIndex = threadIdx().x - 1
totalThreads = blockDim().x * gridDim().x
temp = 0cacheIndex is the index we will use to write an element to the array of shared memory we created. Remember shared memory is only accessible within the current block, so we do not need to worry about making a unique index across blocks like we did for tid. We set it to threadIdx().x - 1 so that each thread is writing to a separate location in shared memory - otherwise threads could overwrite the results calculated by other threads. totalThreads is the product of the number of threads in each block (blockDim().x) and the number of blocks in the grid (gridDim().x). This is equal to the total number of threads we have deployed using @cuda.
Now we are ready to start calculating the dot product:
# Iterate over vector to do dot product in parallel way
while tid < N
temp += a[tid + 1] * b[tid + 1]
tid += totalThreads
endFor context, N is the number of elements in a (which is the same as the number of elements in b). So while tid is less than the number of elements in a, we increment the value of temp by the product of a[tid + 1] and b[tid + 1] - this is the core operation in a vector dot product. Then, we increment tid by the total number of threads deployed on the GPU. This line enables us to carry out dot products for vectors which have more elements than the total number of threads on our GPU (ie. if N > totalThreads).
After exiting the while loop, we write the value calculated in temp to shared memory:
# set cache values
cache[cacheIndex + 1] = tempIn the next step of the kernel, we want to sum up all the values stored in shared memory. We do this by finding the sum of all the elements in cache. But remember that each thread is running asynchronously - just because one thread has finished executing the line:
cache[cacheIndex + 1] = tempDoes not mean that all threads have executed that line. To avoid trying to sum the elements of cache before they have all been written, we need to make the threads all pause and wait until every thread has reached the same line in the kernel. Fortunately, such a function exists as part of CUDAnative:
# synchronise threads
sync_threads()When each thread reaches this line, it pauses in its execution of the kernel until all of the threads in that block have reached the same place. Then, the threads restart again.
Now all the threads have written to shared memory, we are ready to sum the elements of cache:
# In the step below, we add up all of the values stored in the cache
i::Int = blockDim().x ÷ 2
while i!=0
if cacheIndex < i
cache[cacheIndex + 1] += cache[cacheIndex + i + 1]
end
sync_threads()
i = i ÷ 2
endHere, we initialise i as half of the total number of threads in a block. In the first iteration of the while loop, if cacheIndex is less than this number, we add the value stored at cache[cacheIndex + i + 1] to the value of cache[cacheIndex + 1]. Then we synchronise the threads again, divide i by two and enter the second while loop iteration. If you work through this conceptually, you should see that provided the number of threads in a block is a power of 2 (ie. can be expressed as 2^n), eventually the value at cache[1] will be equal to the sum of all the elements in cache.
Now we need to write the value of cache[1] to c (remember that we can not directly return the value of cache[1] due to the requirement that the kernel must always return nothing).
# cache[1] now contains the sum of vector dot product calculations done in
# this block, so we write it to c
if cacheIndex == 0
c[blockIdx().x] = cache[1]
end
return nothing
endAnd that is it! We have made it through the kernel. Now all we have to do is run the kernel on a GPU:
function main()
# Initialise variables
N::Int64 = 33 * 1024
threadsPerBlock::Int64 = 256
blocksPerGrid::Int64 = min(32, (N + threadsPerBlock - 1) / threadsPerBlock)
# Create a,b and c
a = CuArrays.CuArray(fill(0, N))
b = CuArrays.CuArray(fill(0, N))
c = CuArrays.CuArray(fill(0, blocksPerGrid))
# Fill a and b
for i in 1:N
a[i] = i
b[i] = 2*i
end
# Execute the kernel. Note the shmem argument - this is necessary to allocate
# space for the cache we allocate on the gpu with @cuDynamicSharedMem
@cuda blocks = blocksPerGrid threads = threadsPerBlock shmem =
(threadsPerBlock * sizeof(Int64)) dot(a,b,c, N, threadsPerBlock, blocksPerGrid)
# Copy c back from the gpu (device) to the host
c = Array(c)
local result = 0
# Sum the values in c
for i in 1:blocksPerGrid
result += c[i]
end
# Check whether output is correct
println("Does GPU value ", result, " = ", 2 * sum_squares(N - 1))
end
main()
main() starts by initialising several variables, including N which sets the size of a, b and c. We also initialise the number of threads we want the GPU to use per block and the number of blocks we want to use on the GPU. Next, we use CuArrays to create a, b and c and to fill a and b. Then, we use @cuda to execute the kernel on the GPU:
@cuda blocks = blocksPerGrid threads = threadsPerBlock shmem =
(threadsPerBlock * sizeof(Int64)) dot(a,b,c, N, threadsPerBlock, blocksPerGrid)Note that in addition to setting the number of blocks and threads we want the GPU to use, we set a value for shmem. shmem describes the amount of dynamic shared memory we need to allocate for the kernel - see below for more details. Since we use @cuDynamicSharedMem to make an array of size threadsPerBlock full of Int64s in the kernel, we need to allocate (threadsPerBlock * sizeof(Int64) bytes of space in advance when we call @cuda.
After executing the kernel on GPU, we copy c back to the host (CPU). At this point, c is an array whose length equals the number of blocks in the grid. Each element in c is equal to the sum of the values calculated by the threads in a block. We need to sum the values of c to find the final result of the vector dot product:
# Sum the values in c
for i in 1:blocksPerGrid
result += c[i]
endFinally, we do a sanity check to make sure the output is correct. For completeness, this is the function sum_squares():
function sum_squares(x)
return (x * (x + 1) * (2 * x + 1) / 6)
endAnd that is it! We now have a complete Julia script which calculates a vector dot product on a GPU, making use of shared memory and synchronisation. In the next section, we will discuss streaming.
A Note on Static and Dynamic Allocation
In the first line of the kernel, we call @cuDynamicSharedMem. @cuDynamicSharedMem has a sister function, @cuStaticSharedMem. Like @cuDynamicSharedMem, @cuStaticSharedMem allocates arrays in shared memory. However unlike @cuDynamicSharedMem, @cuStaticSharedMem allocates arrays statically rather than dynamically. Memory that is statically allocated is allocated at compilation time, whereas memory that is dynamically allocated is allocated at program execution. We used @cuDynamicSharedMem in our example because one of the command line arguments for @cuDynamicSharedMem was a kernel command line argument (threadsPerBlock). Because the value of the kernel command line argument is not known at compilation time, dynamic rather than static memory allocation was required.
A consequence of using dynamic rather than static memory allocation was that we had to specify how much memory @cuDynamicSharedMem would need in our @cuda call. Otherwise, there is no way @cuda could know the correct amount of shared memory to allocate in advance, since @cuDynamicSharedMem does not determine how much shared memory it will need until it runs.
A Note on Types
You may have noticed that we typed some of the variables in this example. One reason for this is that type conversions are forbidden on the kernel. If we need a variable to be a particular type for kernel execution, it is therefore often easiest to specify its type immediately on creation. We discuss this and other Julia specific GPU software concerns in Challenges in Julia GPU Software Development